Modernize IBM Datastage Migrate - Faster, Smarter. 🚀
Datasheet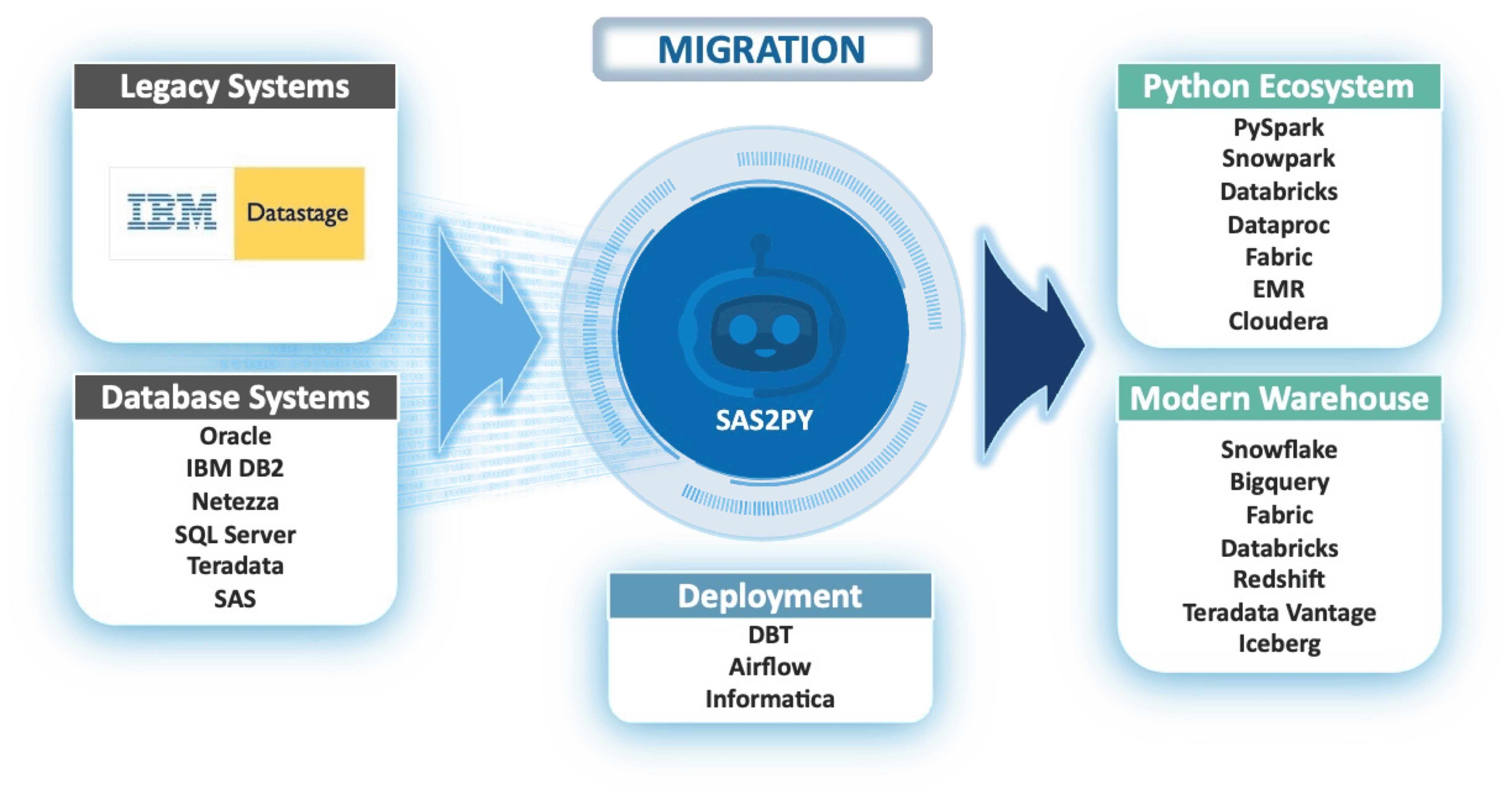



SAS2PY automates the end-to-end migration of legacy IBM DataStage environments— transforming job designs, workflows, and data pipelines into scalable, cloud-native architectures optimized for performance, flexibility, and long-term sustainability.
SAS2PY preserves metadata, accelerates migration timelines, and provides full visibility from original IBM DataStage jobs to optimized modern outputs—enabling a seamless, secure, and verifiable modernization of your data engineering infrastructure.

SAS2PY ensures your IBM DataStage migration is not only fast—but also functionally accurate, fully traceable, and ready for production at scale.
SAS2PY automates the conversion of legacy IBM DataStage jobs, flows, and ETL logic into Python, SQL, and modern cloud-native pipelines. It replaces months of manual re-engineering with a parser-driven, traceable process.
You can migrate up to 100,000 lines of DataStage ETL logic in under 10 minutes, cutting project timelines by up to 90% compared to manual refactoring.
Absolutely. SAS2PY scales across millions of lines of DataStage logic—including shared containers, sequences, parallel jobs, and nested transformations—while preserving control flow and dependencies.
We use row-by-row and aggregate-level validation, including schema checks and output comparisons, to ensure 100% alignment between your original DataStage outputs and the modernized environment.
Yes. By retiring DataStage and transitioning to open-source and cloud-native platforms, customers typically save 50–75% on software, infrastructure, and support.
SAS2PY performs schema mapping, metadata comparison, row-level output matching, and regression tests to ensure all DataStage outputs are faithfully reproduced in the target environment.
Manual migrations are slow, error-prone, and costly. SAS2PY offers automation, auditability, and full traceability—reducing both risk and cost while ensuring consistency across jobs.
Migrated logic can be deployed into Airflow, DBT, Databricks, Snowflake, or any modern pipeline orchestration tool using Python modules, SQL scripts, or parameterized notebooks.