How accurate is the conversion?
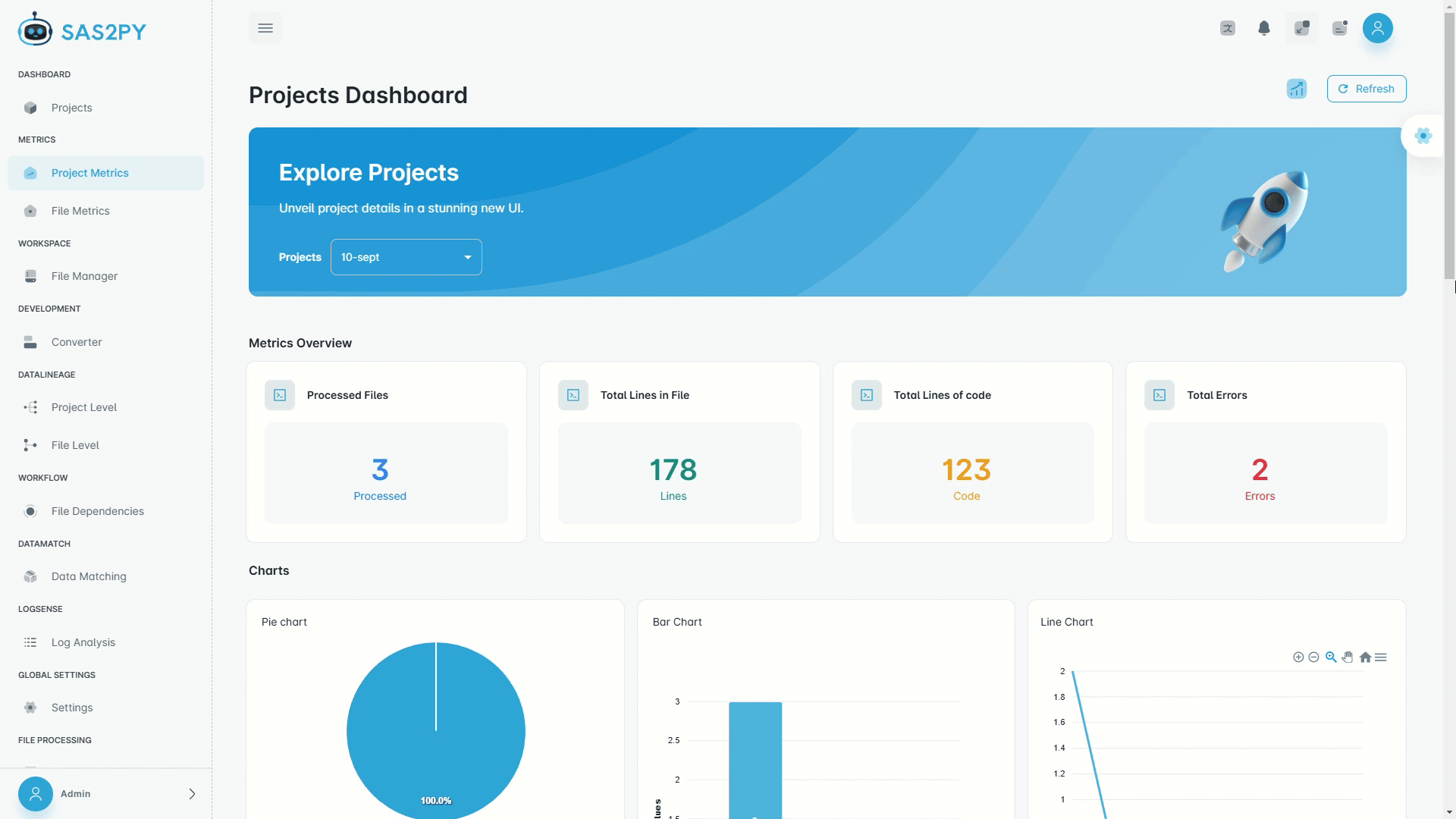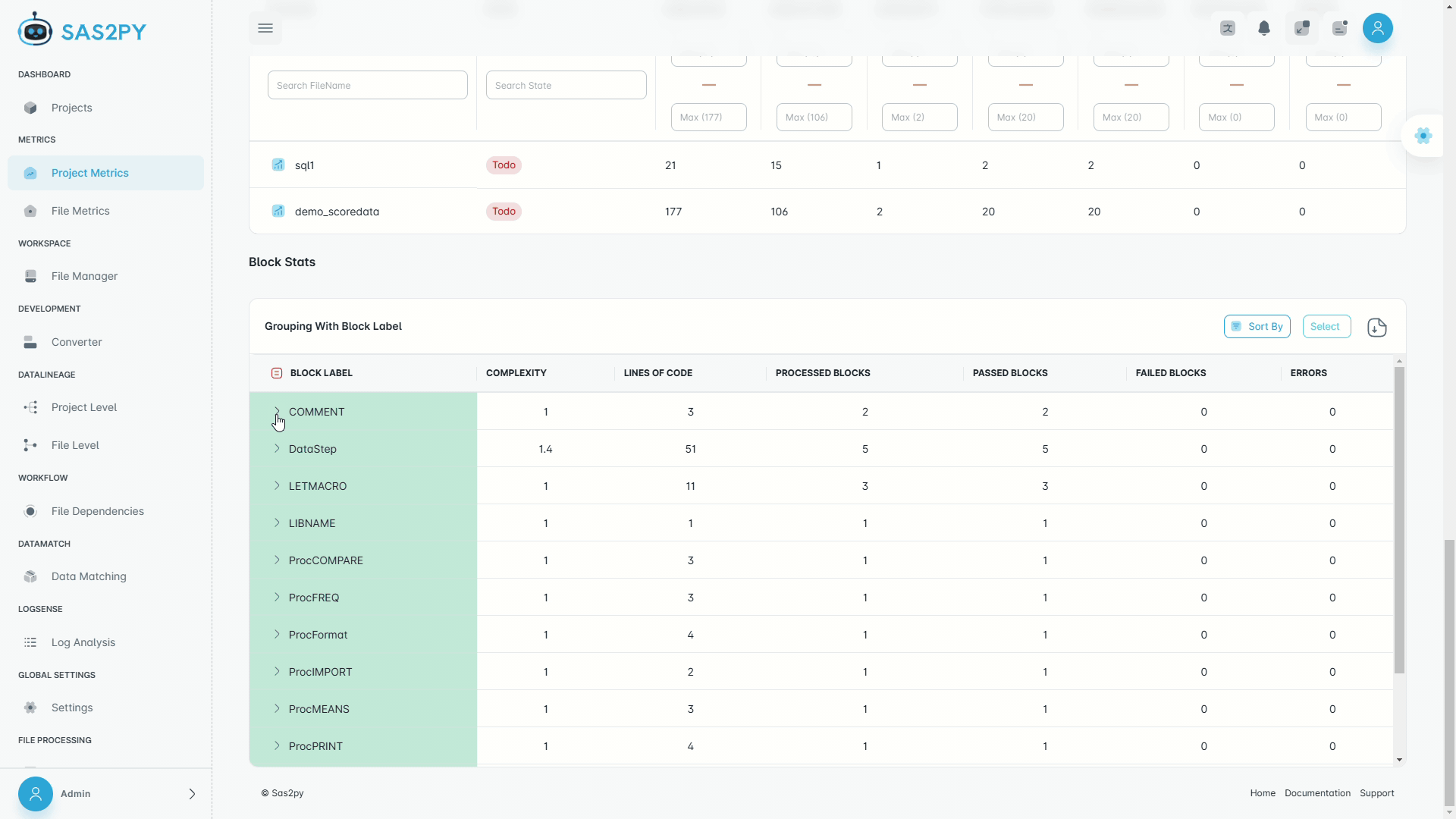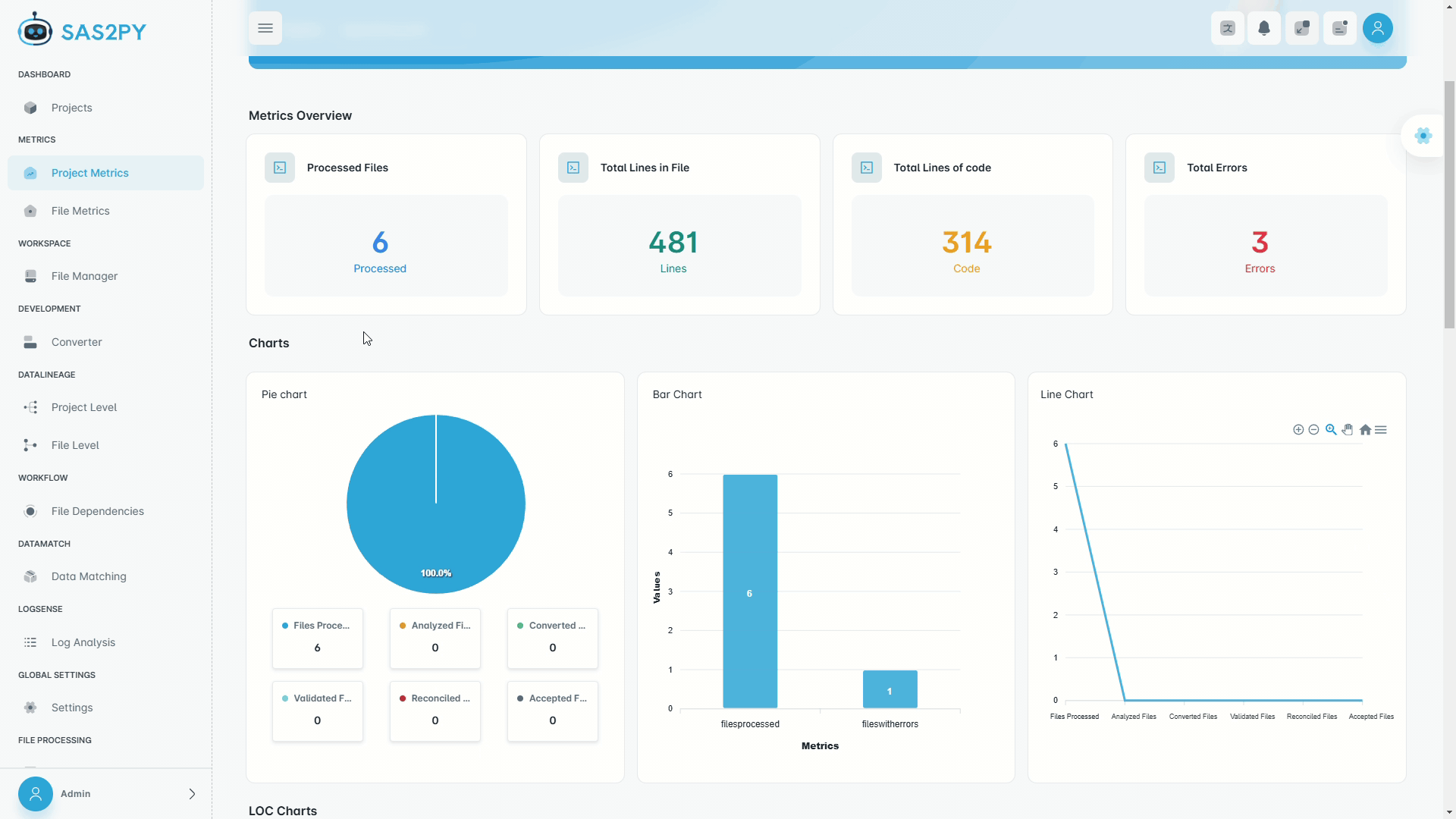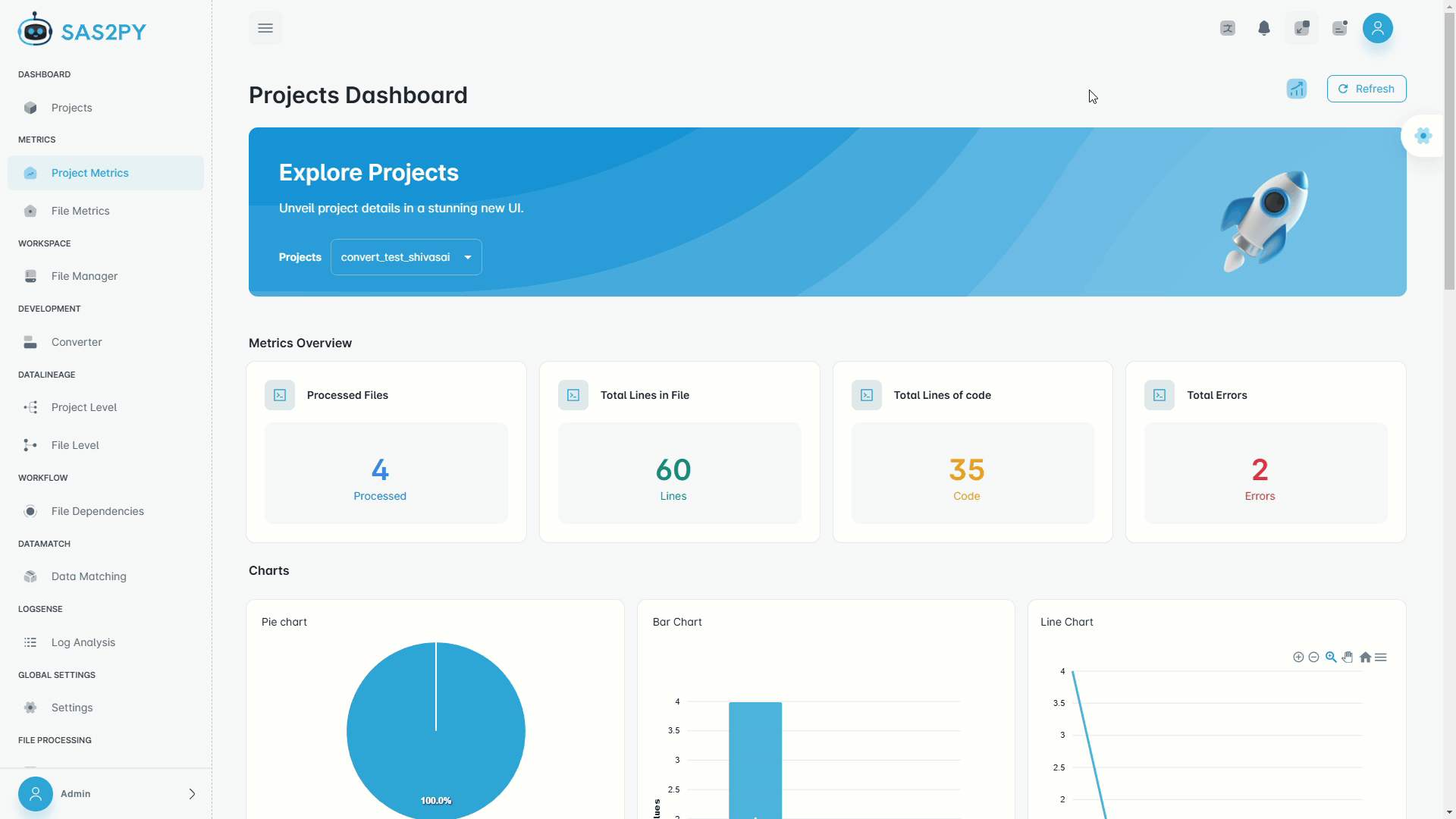
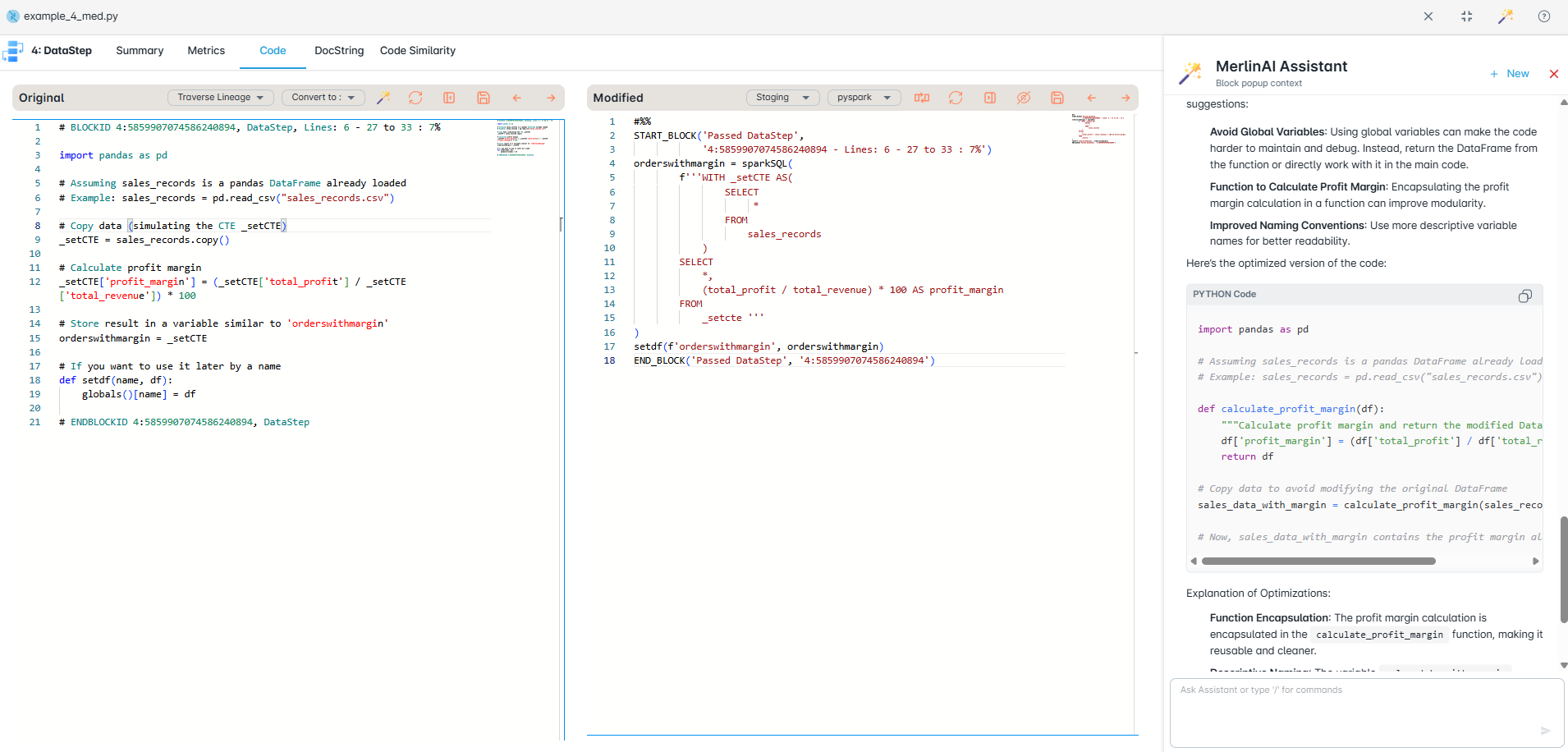
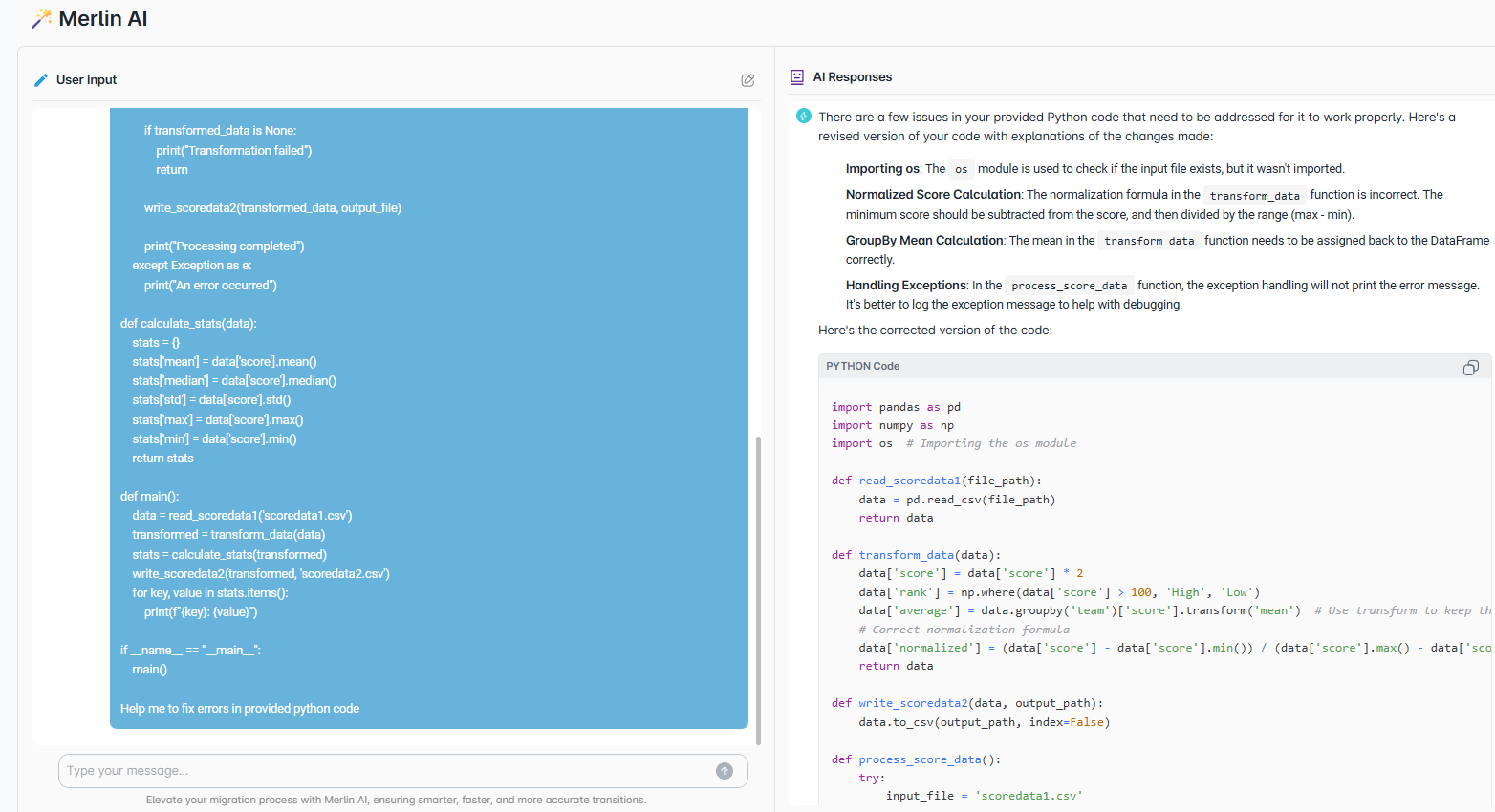
Deterministic parsers handle 95%+ of typical SAS code out of the box. Optional AI resolves ambiguous macros and undocumented logic, pushing accuracy higher. Every conversion ships with a validation report proving row-level parity.
Does our code leave our network?
Not unless you choose to. Self-hosted SAS2PY runs on-premises or in your own cloud — Docker, Kubernetes, or OpenShift, air-gapped capable — and your code never leaves your environment. Prefer zero setup? The SaaS portal at app.sas2py.com runs the same engine in our secure cloud.
How do you prove outputs match?
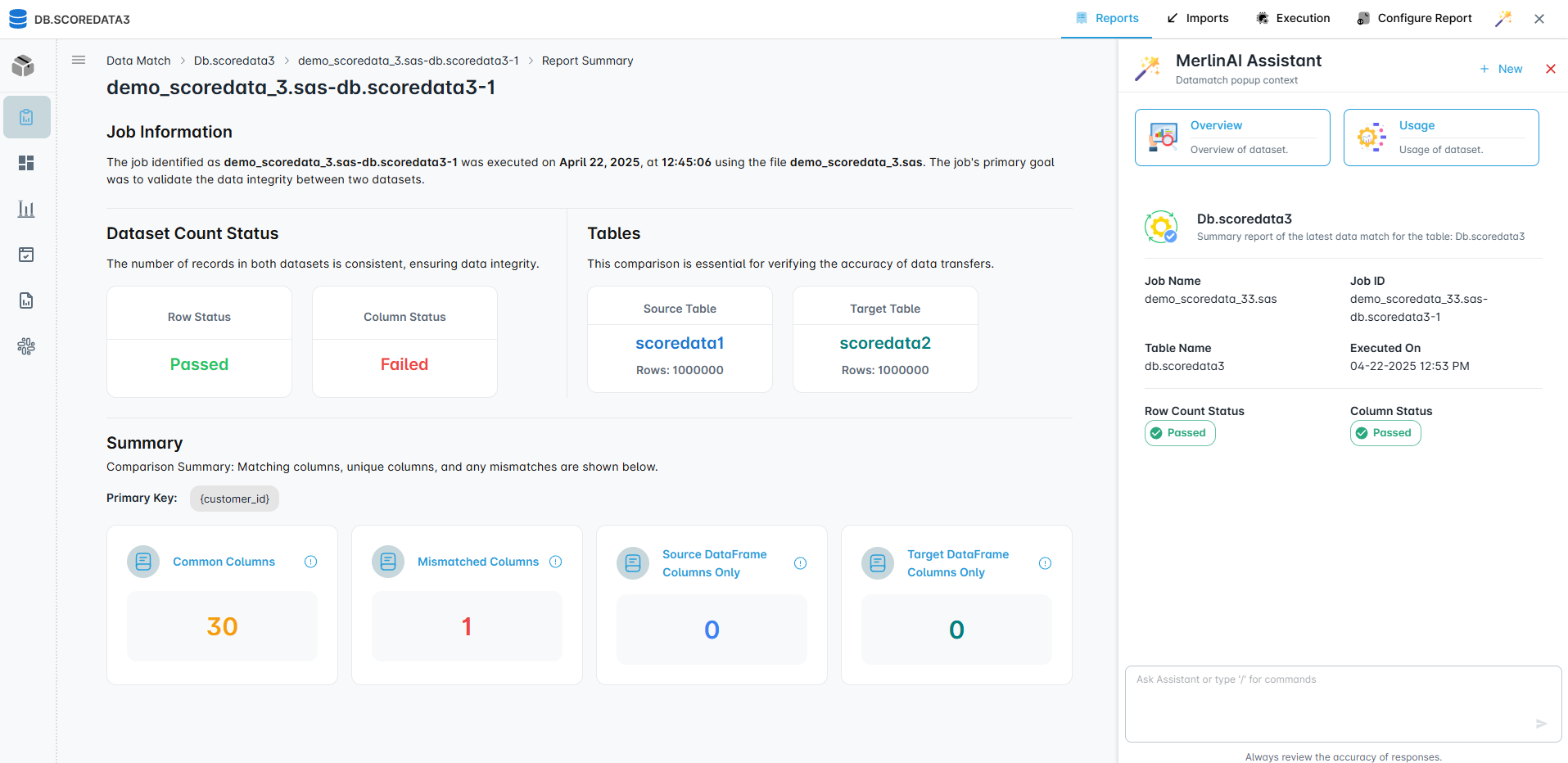
Partitioned validation compares row-level and aggregate outputs between legacy SAS and modern targets. Automatic schema checks, data matching reports, and exception trails provide audit-ready evidence.
How long does it take for our estate?
Deployment itself takes under an hour. Migration Readiness on estates from 100K to 100M lines runs 1–8 weeks, and a Full Pilot on 10K lines takes about 2 weeks — both run by your own team on your own schedule.
Do we need consultants or a services engagement?
Only if you want one. SAS2PY is self-service software: you run the conversion and keep the output, with no required services contract or RFP. But if you'd rather have it done for you, our Guided Migration service puts our engineers on the conversion end to end.
Our team only knows SAS — is this still for us?
Yes. Generated code ships documented and readable, with mapping sheets that tie every output back to the original SAS. Start with the SaaS portal or a guided pilot where we do the conversion, and your team ramps up on the target platform through training and handover.
What targets do you support?
Databricks notebooks, PySpark, Snowflake SQL, Snowpark, BigQuery, Polars, Fabric, Redshift, Cloudera, DBT models, and Python — with comments, mapping sheets, and auto-generated documentation.
How do we get started?
Fastest path: email us for access to the SaaS portal at app.sas2py.com and start converting from your browser. Prefer your own environment? Get a pilot license and install the same day. Or send a representative sample and we'll return converted, validated output and a complexity report, free. hello@sas2py.com