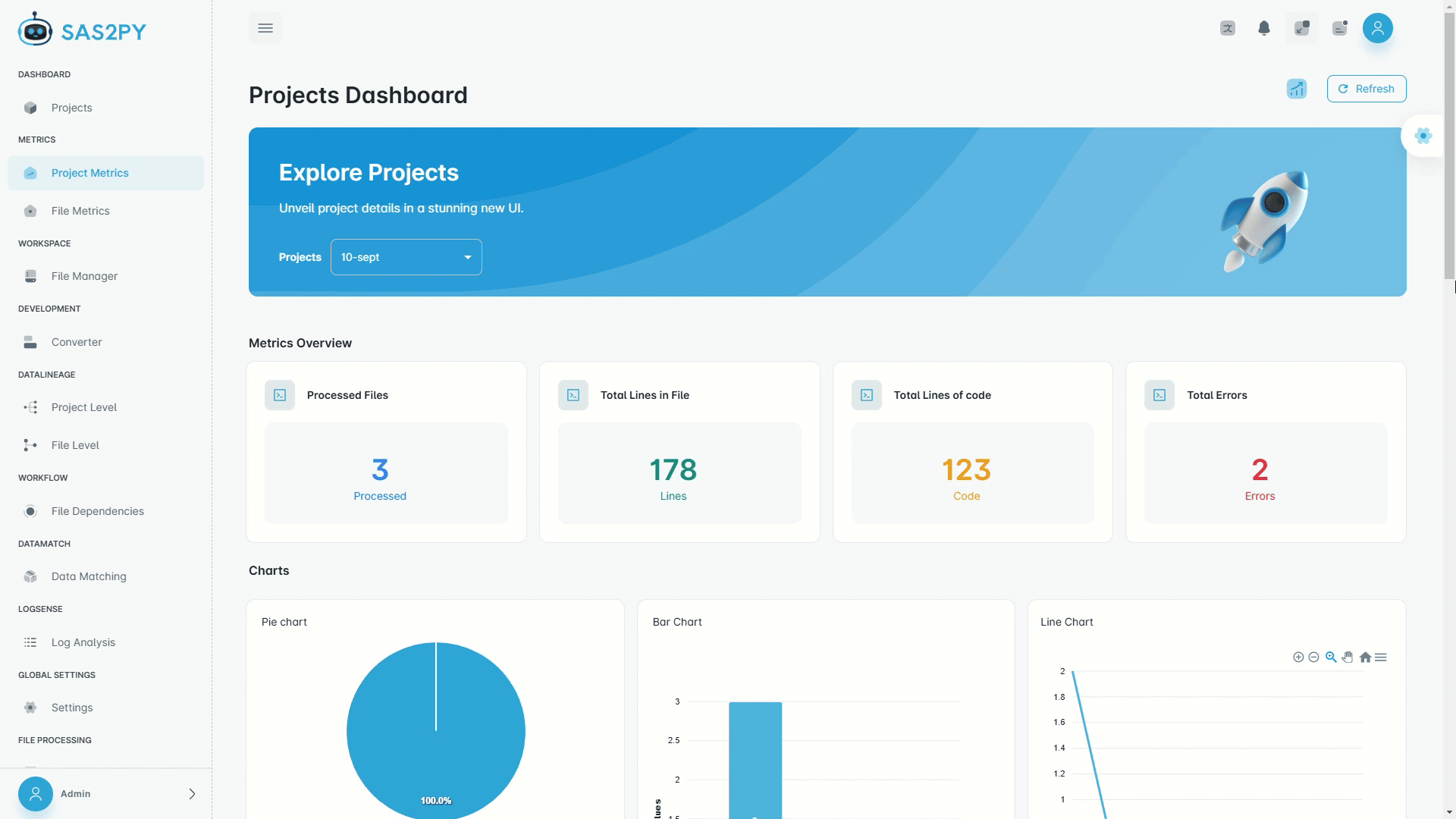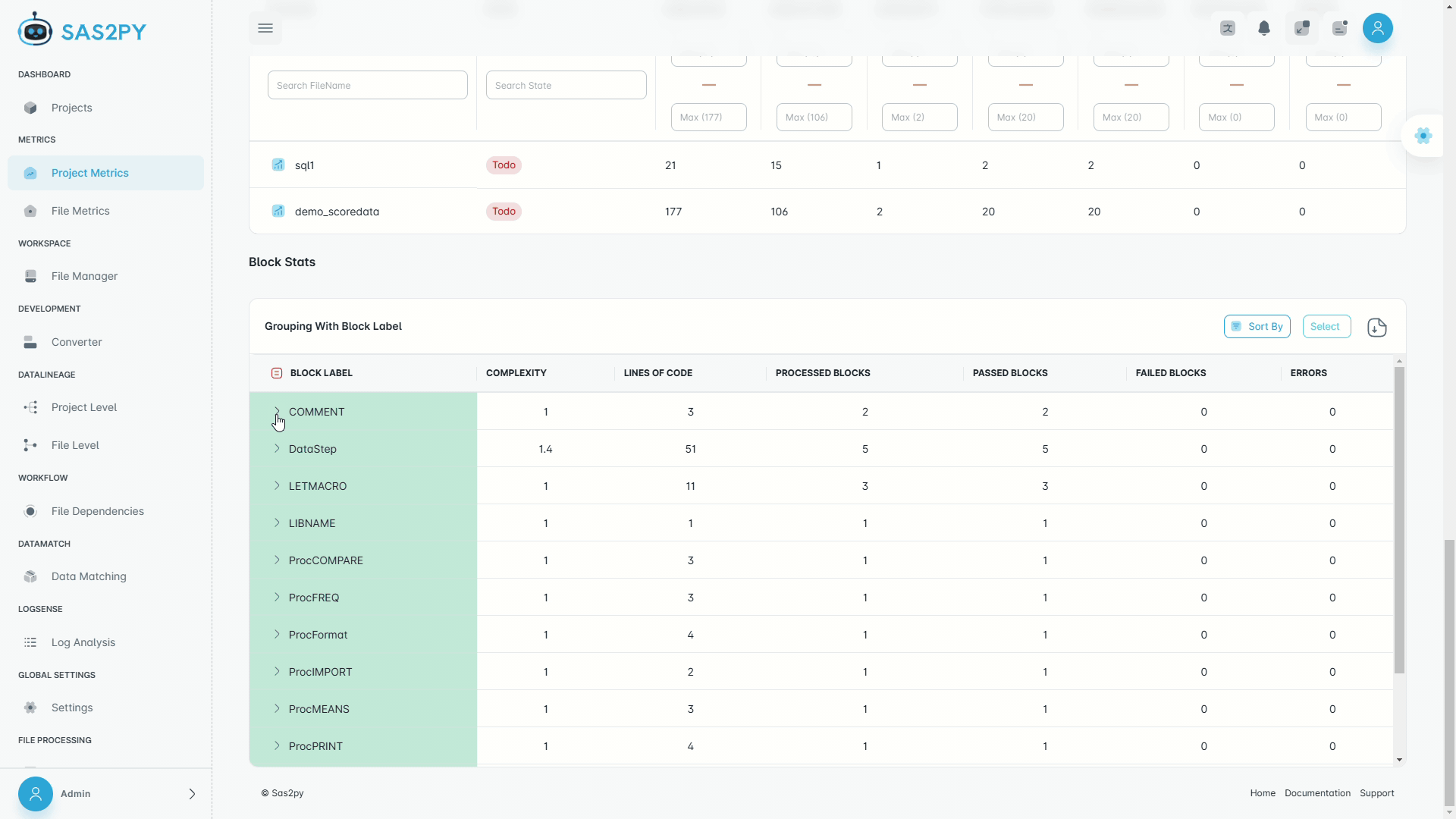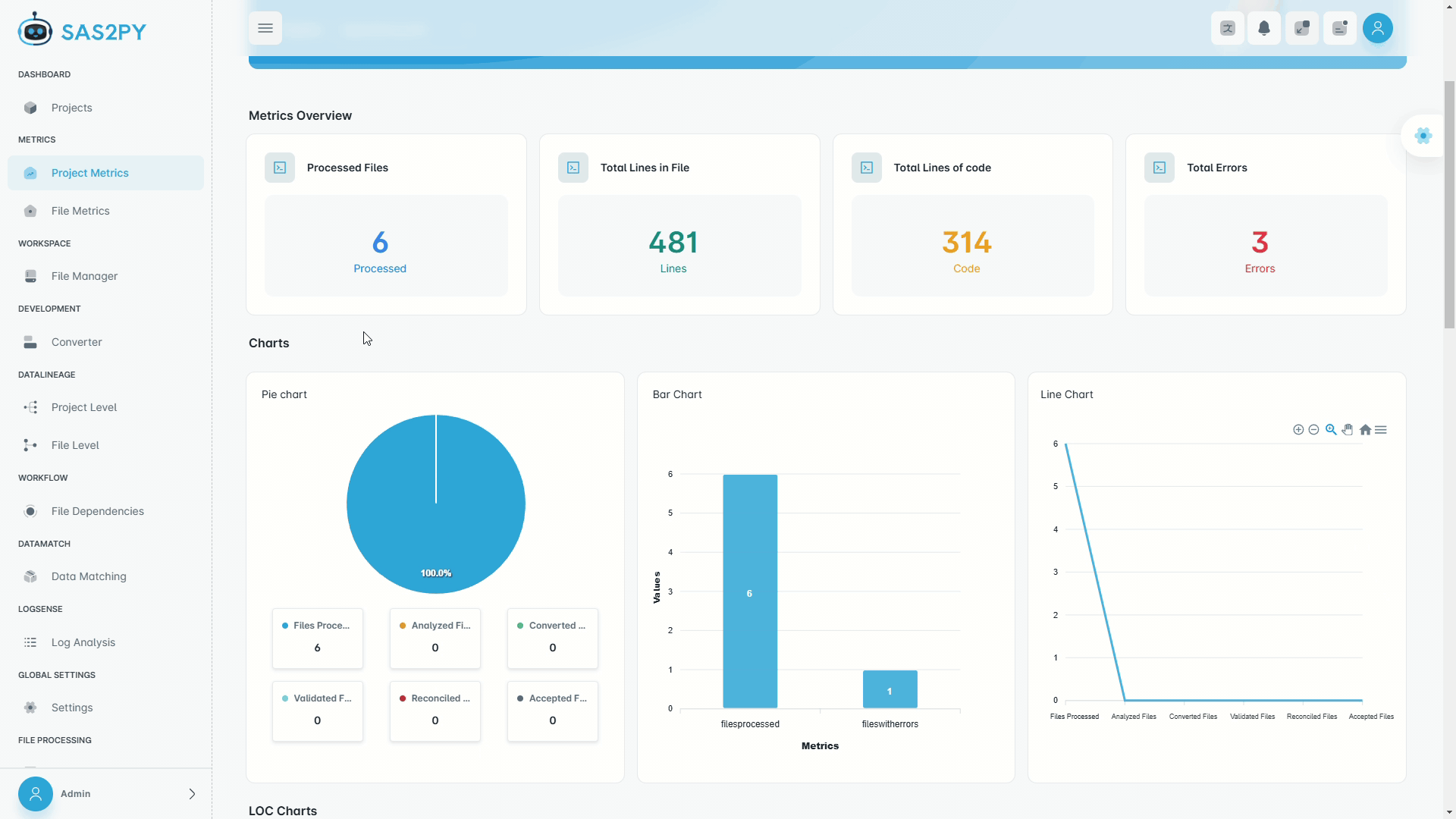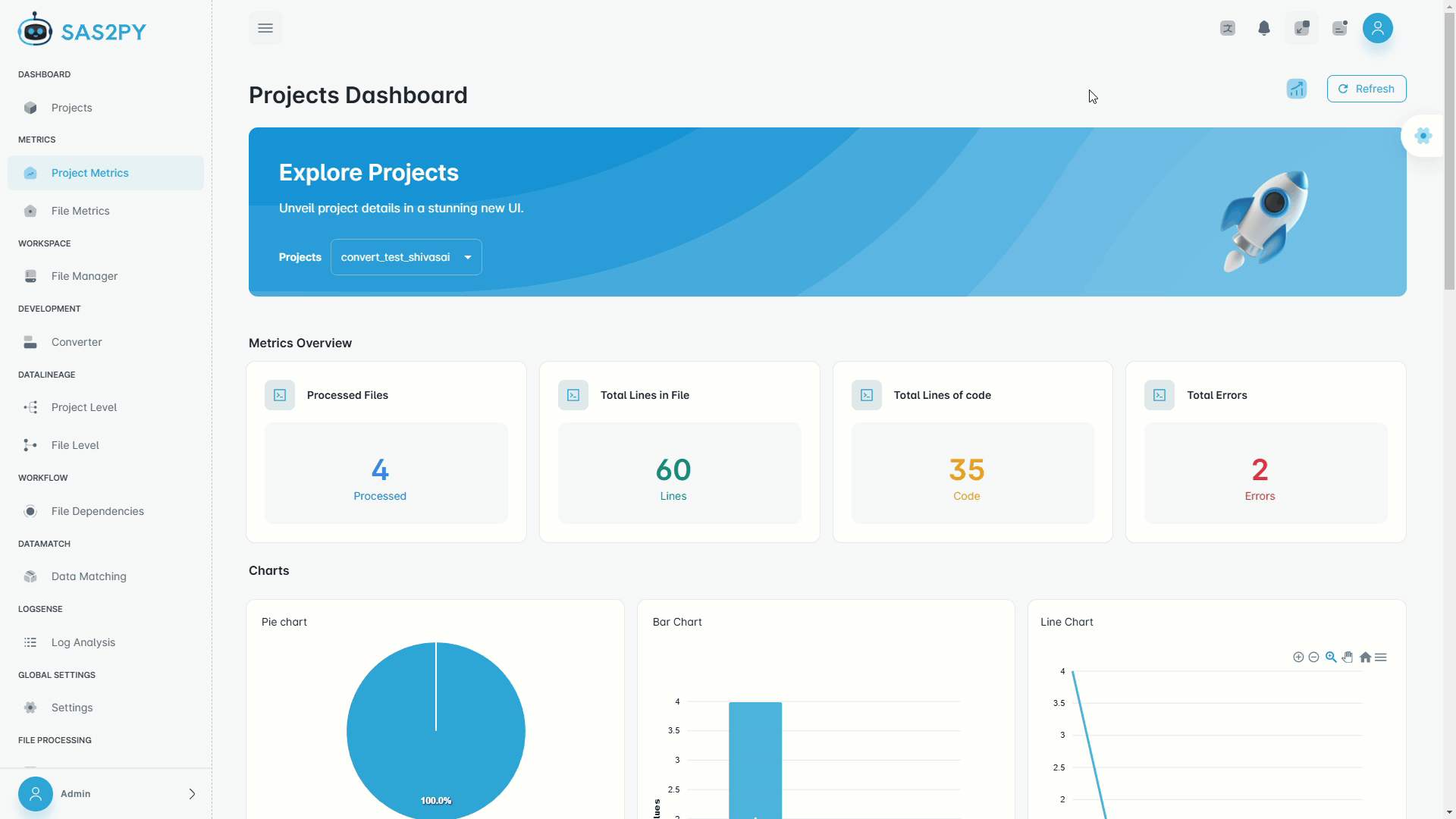
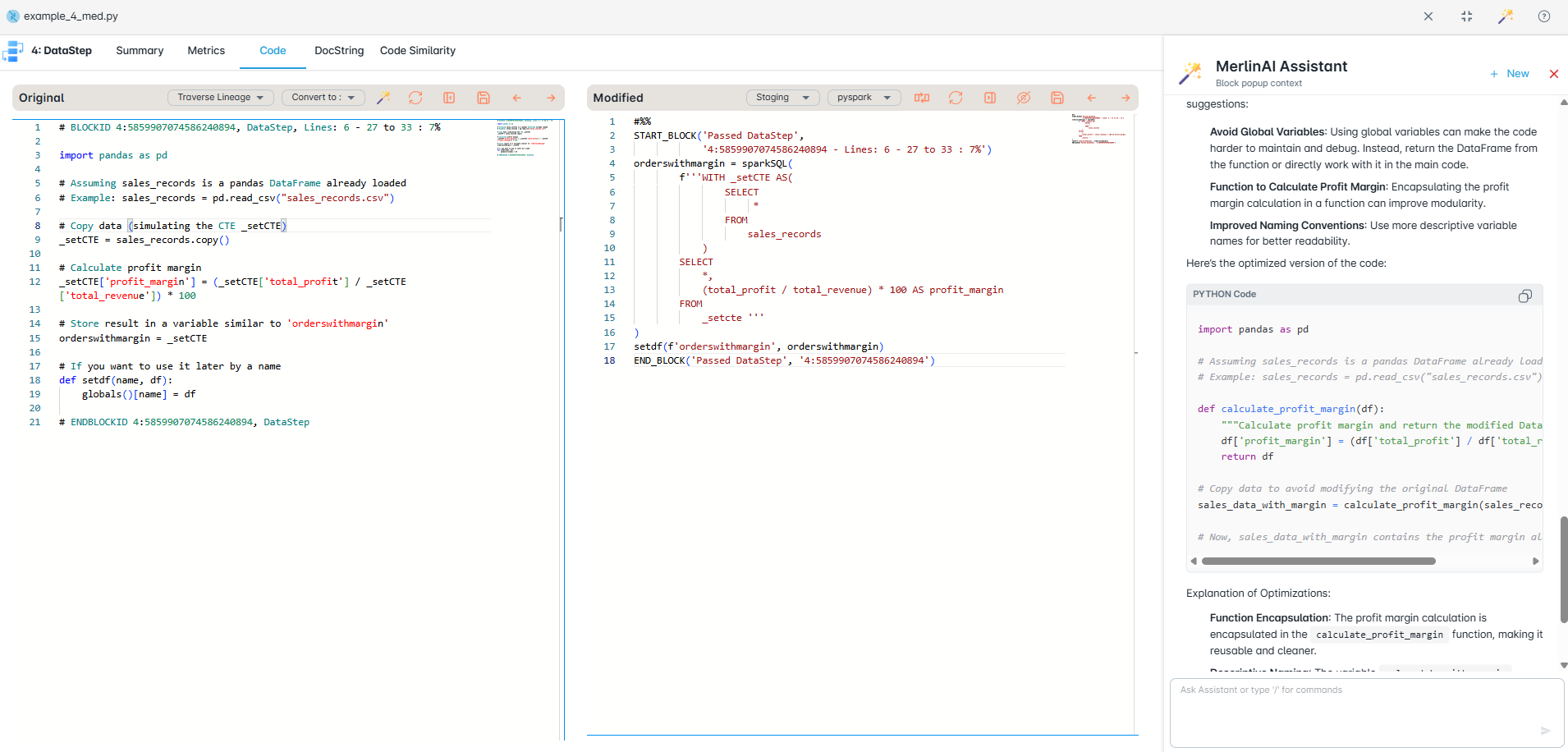
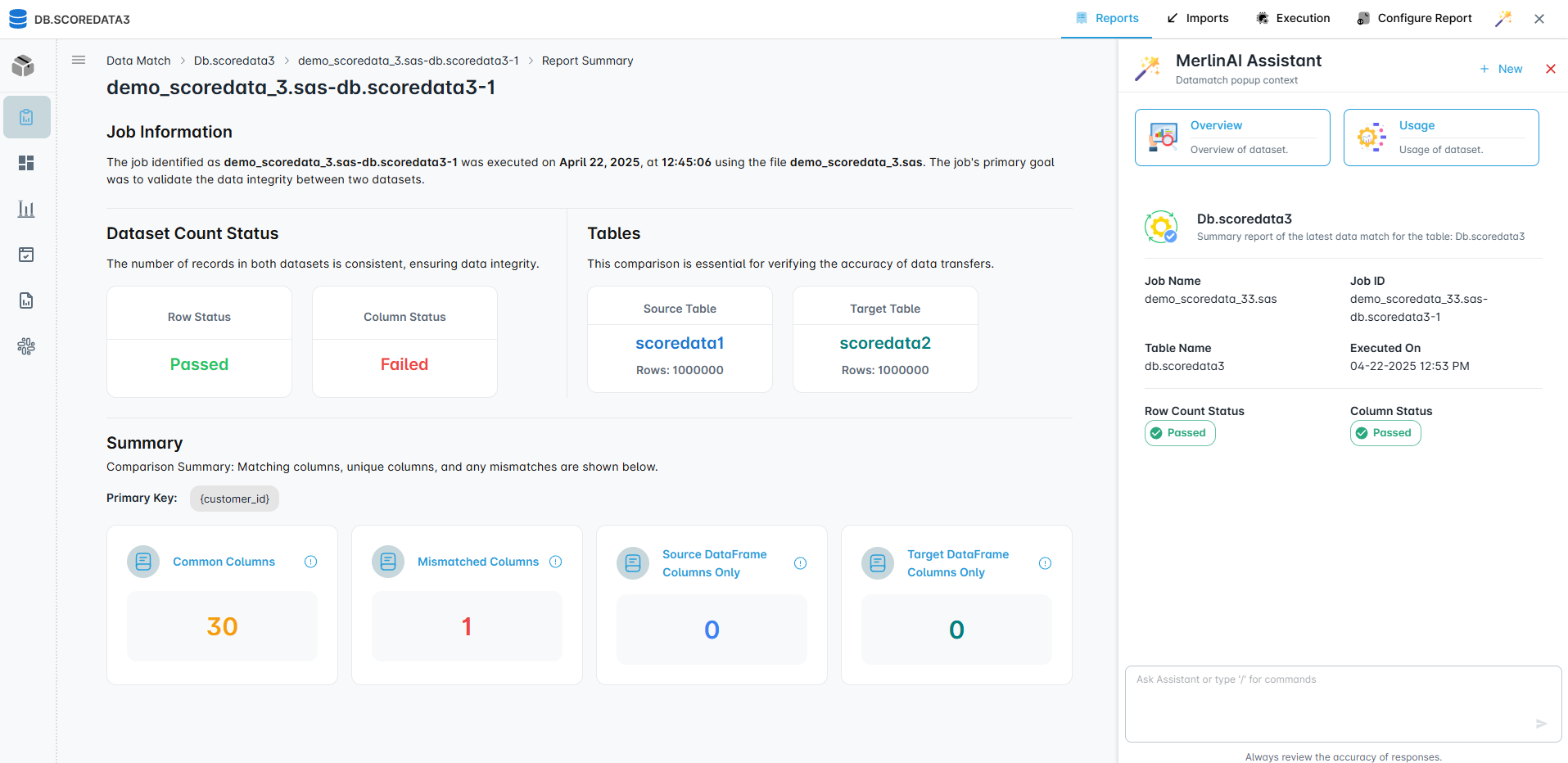
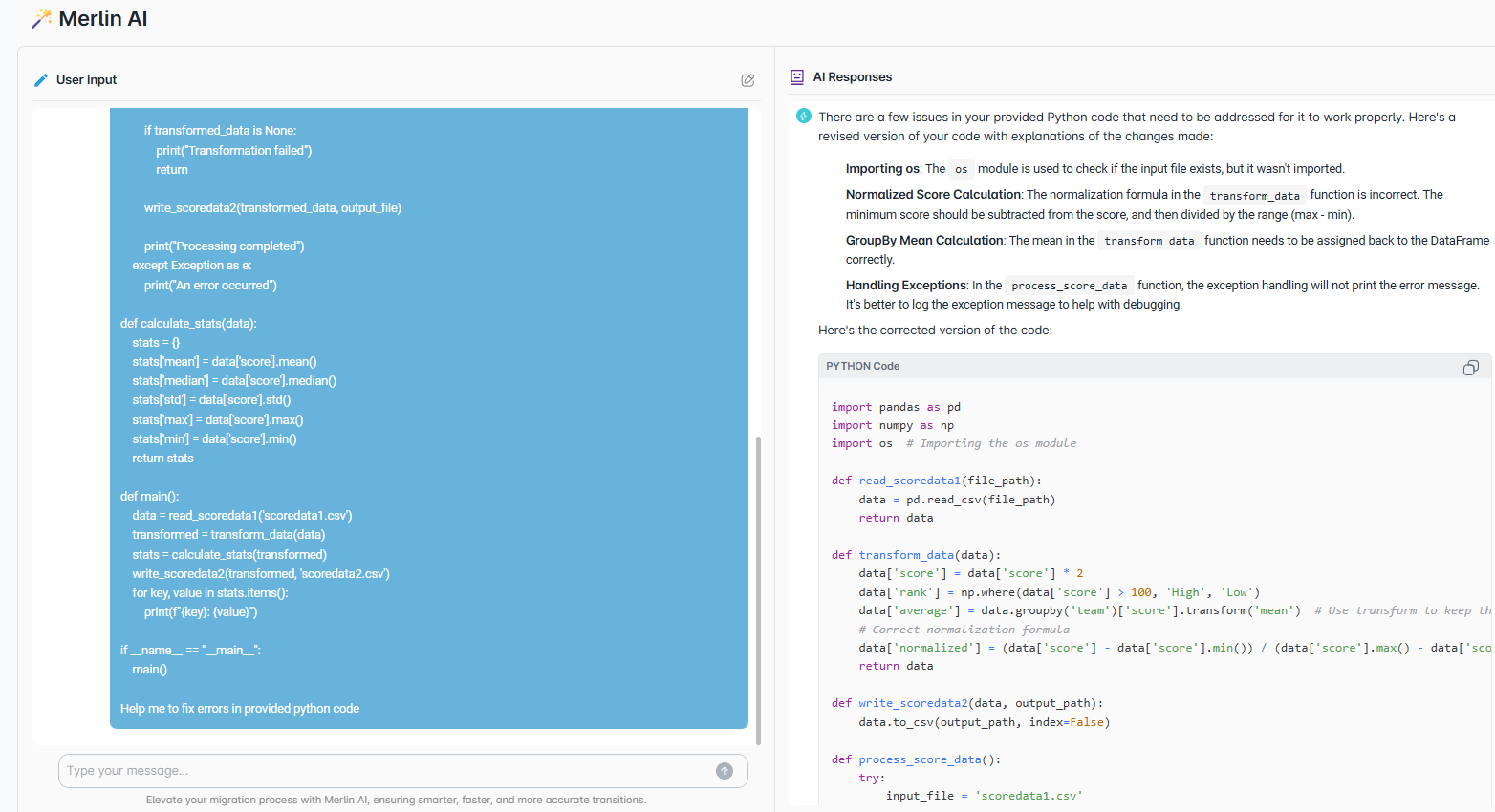
Discovery
1 – 8 weeks- Full estate scan — inventory every program, macro, and job
- Lineage & dependency mapping — visual diagrams of all data flows
- Complexity & risk scoring — conversion difficulty per program
- Phased migration roadmap — wave plan, SOW, and RACI
- 10 structured deliverables — ready for steering-committee approval